
Improving feature stability during upsampling–spectral artifacts and the importance of spatial context
Shashank Agnihotri, Julia Grabinski, Margret Keuper
Published in European Conference on Computer Vision, 2024
[pdf] [bibtex]

Shashank Agnihotri, Julia Grabinski, Margret Keuper
Published in European Conference on Computer Vision, 2024
[pdf] [bibtex]
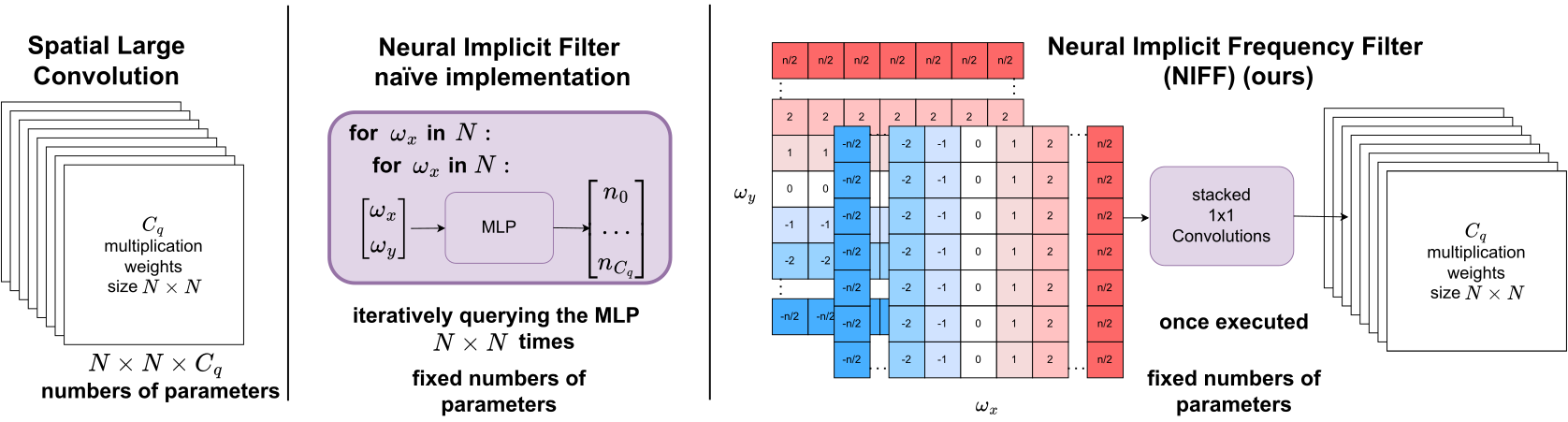
Julia Grabinski, Janis Keuper, Margret Keuper
Published in Transactions on Machine Learning Research Featured Certification, 2024
[pdf] [github] [bibtex]

Shashank Agnihotri, Kanchana Vaishnavi Gandikota, Julia Grabinski, Paramanand Chandramouli, Margret Keuper
Published in International Conference on Computer Vision Workshops, 2023
[pdf] [bibtex]
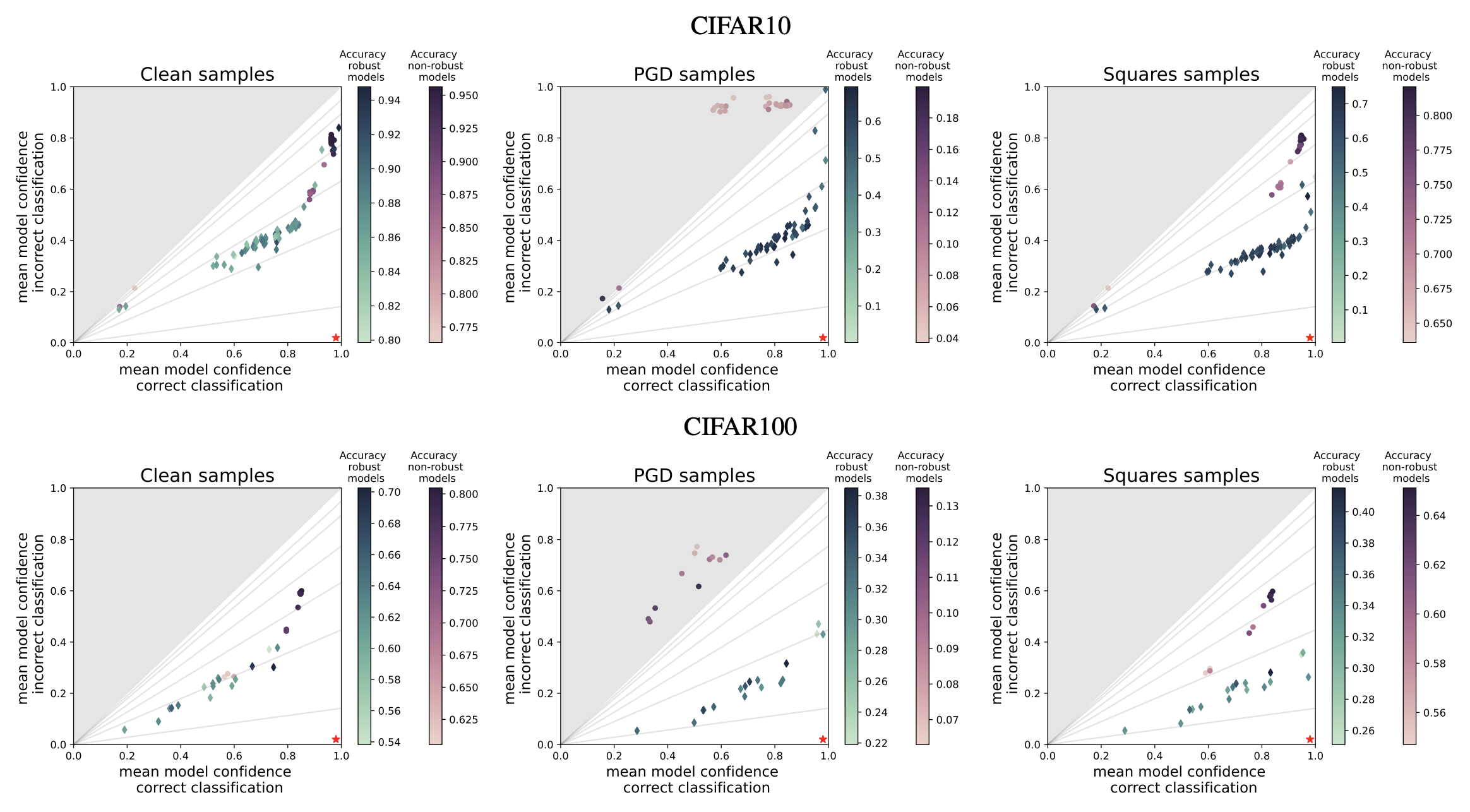
Julia Grabinski, Paul Gavrikov, Janis Keuper, Margret Keuper
Published in Advances in Neural Information Processing Systems, 2022
[pdf] [github] [bibtex]
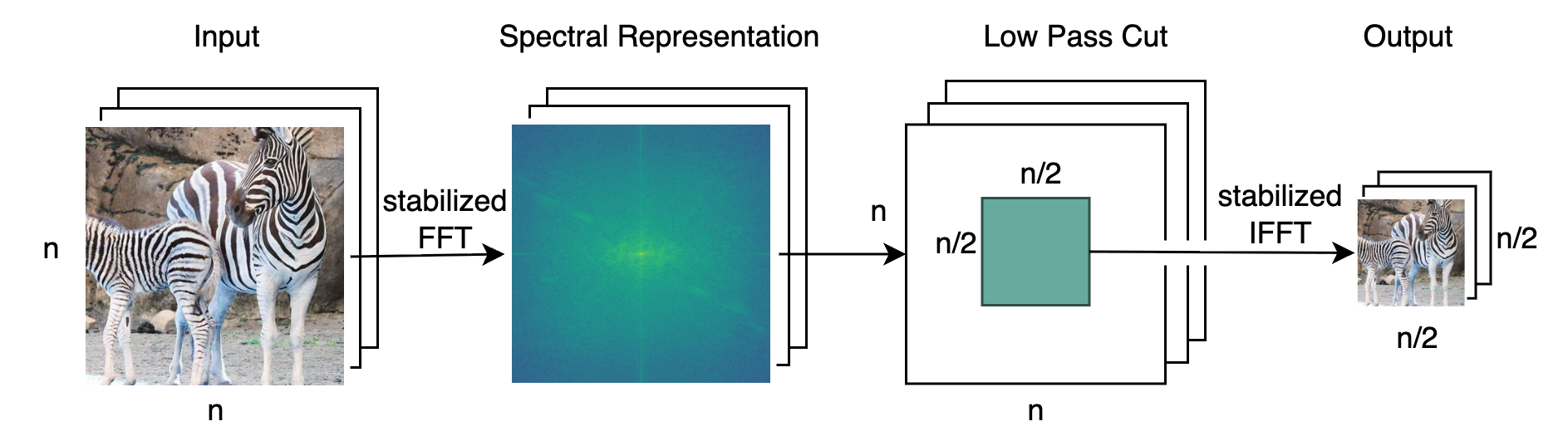
Julia Grabinski, Stefan Jung, Janis Keuper, Margret Keuper
Published in European Conference on Computer Vision, 2022
[pdf] [github] [bibtex]
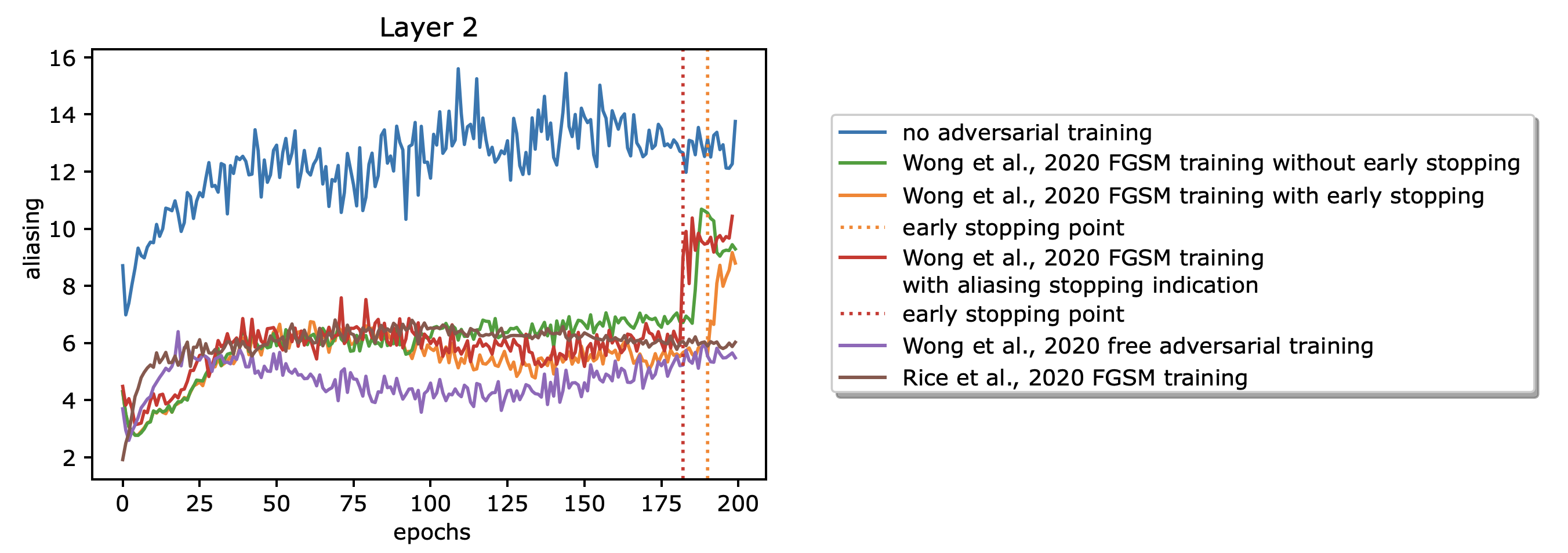
Julia Grabinski, Janis Keuper, Margret Keuper
Published in European Conference on Machine Learning, 2022
[pdf] [bibtex]
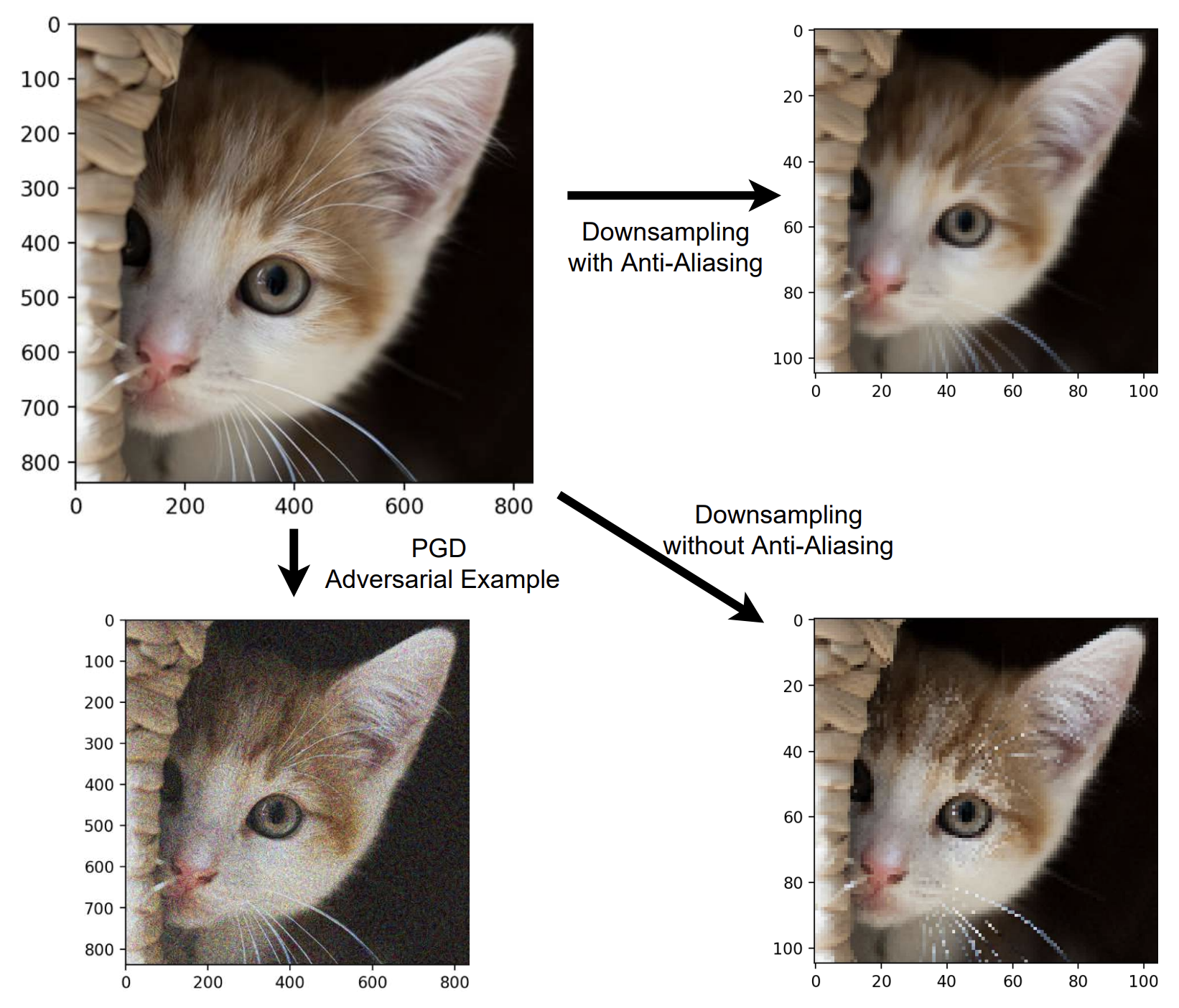
Julia Grabinski, Janis Keuper, Margret Keuper
Published in AAAI-22 Workshop on Adversarial Machine Learning and Beyond, 2022
[pdf] [bibtex]